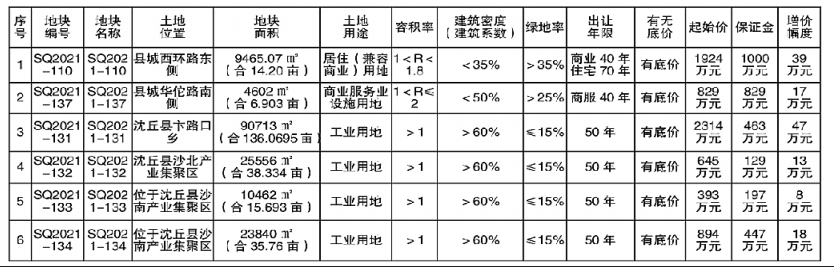
3月21日,中国本土AI创新企业寒武纪正式发布了新款训练加速卡“MLU370-X8”,搭载双芯片四芯粒封装的思元370,集成寒武纪MLU-Link多芯互联技术,主要面向AI训练任务。

寒武纪MLU370-X8智能加速卡首次整合了双芯片四芯粒的思元370,也就是每张卡两颗芯片,每颗芯片内封装两个Die,因此可提供两倍于思元370加速卡的内存、编解码资源。
架构基于Cambricon MLUarch03,支持AI训练加速中常见的FP32、FP16、BF16、INT16、INT8、INT4数据格式计算,峰值性能分别为32TFlops、96TFlops、96TFlops、128Tops、256Tops、512Tops。
该卡采用7nm制造工艺,集成48GB LPDDR5内存,内存带宽614.4GB/s,PCIe 4.0 x16系统接口,整卡最大训练功耗250W,全高全长双插槽设计,系统被动散热。
通过MLU-Link多芯互联技术,提供卡内、卡间互联功能,并专门设计了MLU-Link桥接卡,可实现4张加速卡为一组、8颗思元370芯片全互联。
每张加速卡通讯吞吐性能200GB/s,带宽为PCIe 4.0的大约3.1倍,可高效执行多芯多卡训练、分布式推理任务。
根据官方数据,Cambricon NeuWare SDK实测,在常见的4个深度学习网络模型上,MLU370-X8单卡性能与主流350W RTX GPU相当。
多卡加速,借助MLU-Link多芯互联技术、Cambricon NeuWare CNCL通讯库的优化,8卡环境下达到更优的并行加速比,YOLOv3、Transformer、BERT、ResNet101训练任务中,8卡并行平均性能达350W RTX GPU的155%。
寒武纪未透露对比的NVIDIA 350W RTX GPU是哪一款,从规格来看,350W功耗的目前只有RTX 3090、RTX 3080 Ti。
当然,一个是专用AI加速卡,一个是GPU通用游戏卡,其实没有太大可比性。
MLU370-X8产品定位中高端,与高端训练产品思元290、玄思1000相互结合,进一步丰富了寒武纪的训练算力交付方式,同时与基于思元370芯粒(chiplet)技术构建的MLU370-X4、MLU370-S4智能加速卡协同,形成完整的云端训练、推理产品组合。
-
美法院裁定披露!中兴通讯复牌H股涨60%,A股涨停
头条 22-03-23
-
河南新惠建投拟发行5亿元私募债获上交所受理
头条 22-03-23
-
国家卫健委:不得以没有核酸检测结果为由推诿患者
头条 22-03-23
-
“观堂机场”不合适?商丘机场如何命名,官方回复了
头条 22-03-23
-
银保监会:2021年末国内21家主要银行绿色信贷余额达15.1万亿元
头条 22-03-23
-
南阳银保监分局:推动宛城、卧龙联社合并组建南阳市农商行
头条 22-03-23
-
预制菜“热炒”,河南驶入万亿新赛道 | 豫见预制菜①
头条 22-03-23
-
洛阳市老城区发现1例新冠肺炎无症状感染者
头条 22-03-23
-
河南省金融局将执法检查省内282家典当行、融资租赁、商业保理公司
头条 22-03-23
-
郝以昆任南阳市人社局党组书记,刘建光任南阳市生态环境局党组书记
头条 22-03-23
-
驻马店发布通告!中心城区全员核酸检测
头条 22-03-23
-
哈尔滨市拟废止实行区域性房地产限售政策
头条 22-03-23
-
河南自贸区郑州片区法院发通告:倡导开展网上诉讼
头条 22-03-23
-
新乡中新商业保理获批设立,注册资本1亿元
头条 22-03-23
-
国家发改委发布氢能产业规划:探索设立制氢基地、鼓励氢能企业上市
头条 22-03-23
-
国家卫健委:昨日本土新增“2591+2346”
头条 22-03-23
-
比亚迪在深圳成立融资租赁公司,注册资本10亿元
头条 22-03-23
-
深交所:中兴通讯拟披露重大事项,今日开市起临时停牌
头条 22-03-23
-
理想汽车:4月1日起 理想ONE售价上调至34.98万元
头条 22-03-23
-
旗下第6家上市公司登陆创业板,新希望刘永好的资本版图里都有谁?
头条 22-03-23
-
河南昨日新增本土确诊病例6例
头条 22-03-23
-
通达股份拟中标国家电网1.93亿元采购
头条 22-03-23
-
巴奴总部迁至北京,捞王、七欣天谋求上市,“火锅第三股”之争,将花落谁家?
头条 22-03-23
-
隔夜欧美·3月23日
头条 22-03-23
-
立方风控鸟·早报(3月23日)
头条 22-03-23
-
3月22日0时至20时,焦作新增本土无症状感染者4例
头条 22-03-22
-
个转企、小升规、规改股、股上市、企转新 洛阳最新支持政策来了!
头条 22-03-22
-
宝能集团董事长姚振华:已领取法律文书,公司欠了银行利息
头条 22-03-22
-
广西:做好抵梧旅客家属的接待衔接
头条 22-03-22
-
民航局:将尽快搜寻黑匣子并开展数据分析
头条 22-03-22
-
目前对东航客机坠毁事故原因尚无清晰判断 将全力搜集各方证据
头条 22-03-22
-
东航:飞机起飞前符合适航要求 已联系到全部旅客家属
头条 22-03-22
-
东航:开展“一户一册一专班”的援助服务
头条 22-03-22
-
中原内配为子公司1402万元融资租赁(售后回租)业务提供担保
头条 22-03-22
-
蓝天燃气2021年度净利润升26.45%至4.21亿元 拟10派5元
头条 22-03-22
-
蓝天燃气拟为两家全资子公司提供3.3亿元担保
头条 22-03-22
-
立方风控鸟·晚报(3月22日)
头条 22-03-22
-
直面商业化的钉钉:不仅探索还要快速商业化
头条 22-03-22
-
桂林消防救援支队今日下午已开展失事客机黑匣子搜寻工作
头条 22-03-22
-
阿里、京东、拼多多:努力活成“友商”的样子
头条 22-03-22
-
同程旅行2021年营收75.4亿元,同比增长27.1%
头条 22-03-22
-
总投资50亿元,漯河一高端手机精密部件生产基地项目签约
头条 22-03-22
-
河南太康新增3例阳性,详情公布
头条 22-03-22
-
通道业务规模压降近8万亿 信托业本轮调整或将见底
头条 22-03-22
-
焦作最新通告:人员限制流动!车辆限制流动!暂停堂食
头条 22-03-22
-
南阳今年实施公共停车场建设工程,新增车位5000个
头条 22-03-22
-
河南省财政下达9.7亿元专项资金支持林业发展
头条 22-03-22
-
河南能源:郑州农商银行15亿元中长期贷款落地
头条 22-03-22
-
财政部:2022年2月全国发行新增债券4939亿元
头条 22-03-22
-
检察机关依法分别对王文生、林洪、任晓冬、陆世成提起公诉
头条 22-03-22
-
即日起,焦作市中小学校暂停线下教学
头条 22-03-22
-
国家医保局同意河南、重庆提出的新冠病毒抗原检测服务收费方式
头条 22-03-22
-
疫情什么时候结束?国家卫健委专家:需要这四个条件
头条 22-03-22
-
郑州48号通告:对部分区域实行分类管理
头条 22-03-22
-
突然爆雷!“万门大学”跑路了
头条 22-03-22












































































- 寒武纪发布全新AI训练GPU 首次整合了双芯2022-03-23
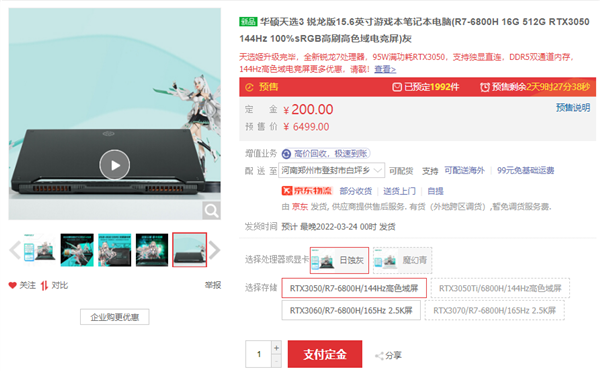
- 华硕天选3游戏本预售:锐龙7 6800H配满功2022-03-23
- 性能飙升66%!AMD发布3D缓存版EPYC 首款2022-03-23
- AMD Zen4处理器已出货:x86首次升级96核192线程2022-03-23
- 华硕“电竞红蜘蛛”秒杀大促 双2.5G网口支2022-03-23
- 「司法行政动态」建设智慧矫正 维护社会稳2022-03-23
- 河南中小学幼儿园名师,骨干教师名单公布,2022-03-23
- 美法院裁定披露!中兴通讯复牌H股涨60%,A2022-03-23
- 同上一堂课 一起向未来|气象科普公益讲座2022-03-23
- 河南新惠建投拟发行5亿元私募债获上交所受2022-03-23
- 范县气象台2022年3月23日12时57分发布大风2022-03-23
- 凤泉湖高新区政务服务大厅启用2022-03-23
- 国家卫健委:不得以没有核酸检测结果为由推2022-03-23
- “观堂机场”不合适?商丘机场如何命名,官2022-03-23
- 银保监会:2021年末国内21家主要银行绿色信2022-03-23
- Redmi AX5400路由器首销 配备6路高性能独2022-03-23
- 大疆经纬M30系列无人机发布 热成像激光测2022-03-23
- 北大博士诈骗2600万获刑10年,检察官:令人2022-03-23
- 找工作又快又好?20万求职者竟然都选“她”2022-03-23
- 同上一堂课 一起向未来 | 气象科普公益2022-03-23
- 受疫情影响!郑州疾控系统公开招聘281人,2022-03-23
- 暖新闻丨广西藤县一饭店老板免费为救援队伍2022-03-23
- 创纪录热浪袭击南北两极2022-03-23
- 大疆首款机场发布 具备强大的环境适应性支2022-03-23
- 海南省将支持医疗机构开展数字疗法临床研究2022-03-23
- 甘肃省启动教育收费专项检查 具有连续性重2022-03-23
- 速看!甘肃省最新普通高中学业水平合格性考2022-03-23
- 《安徽省旅游风景道认定基础条件》发布2022-03-23
- 安徽省发布林业科技特派员服务科技强林行动2022-03-23
- 合肥建立物业服务信用信息等级制度 D级以2022-03-23